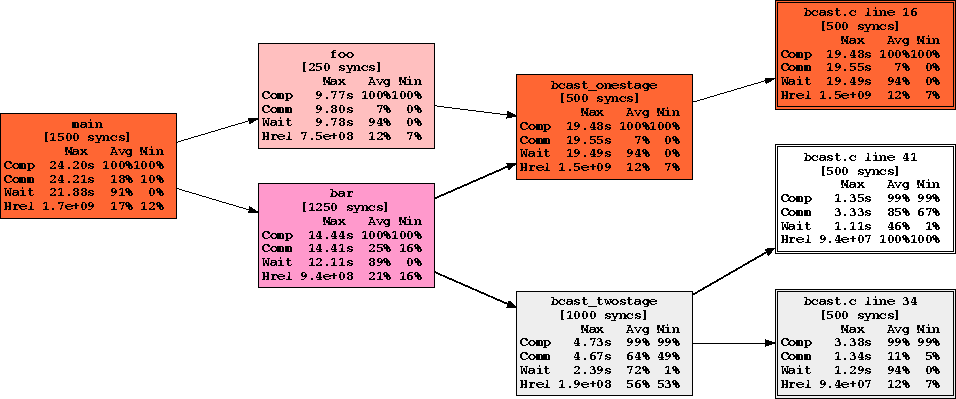
Figure 3: Sample call-graph profile on a 16 processor Cray T3E
Figure 3: Sample call-graph profile on a 16 processor Cray T3E
Figure 3 shows an example call-graph profile for the two broadcast algorithms running on a 16 processor Cray T3E. The call-graph contains a series of interior and leaf nodes. The interior nodes represent procedures entered during program execution, whereas the leaf nodes represent the textual position of supersteps, that is, the line of code containing a bsp_sync. The path from a leaf to the root of the graph identifies the sequence of cost-centres passed through to reach the part of the code that is active when the bsp_sync associated with the given leaf is executed. This path is termed a call-stack and thus a collection of call-stacks comprise a call-graph profile. One of the main advantages of call-graph profiling is that a complete set of unambiguous program costs can be collected at run-time and post-processed. This greatly aids the identification of program bottlenecks. Furthermore, the costs of shared procedures can be accurately apportioned to their parents via a scheme known as inheritance. This allows the programmer to resolve any ambiguities with regard the cost of shared procedures.
The call-graph shown in Figure 3 reflects a program that performs 500 iterations of the one-stage broadcast and 500 iterations of the two-stage. To highlight the features of the call-graph profile, the procedures foo and bar contain procedure calls to the two broadcasting algorithms. In procedure foo, the one-stage broadcast algorithm is executed 250 times, and subsequently, in procedure bar, the one-stage algorithm is executed 250 times, along with 500 iterations of the two-stage.
The graph clearly shows how the costs are inherited from the leaves of the graph towards the root. That is, the top-level procedure main, records the accumulated computation, communication, and idle cost for all the supersteps within the program; whereas interior nodes in the call-graph record information pertaining to supersteps performed during the lifetime of the procedure identified by the interior node.
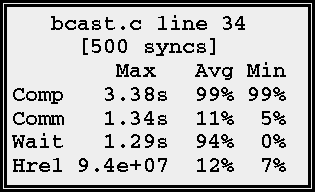
Figure 4: Leaf node
Leaf nodes record: (i) the textual position of the bsp_sync call within the program; (ii) the number of times a particular superstep is executed; and (iii) summaries of the size of h-relation, computation, communication, and idle cost, in terms of the maximum, average, and minimum cost on p processors. The average and minimum cost is given as a percentage of the maximum cost.
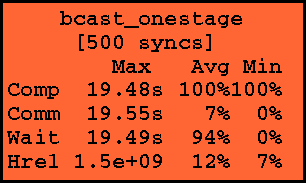
Figure 5: Interior node
Interior nodes record similar information, except that the label of the node is a procedure name, and the accumulated cost is inherited from each of the supersteps executed during that procedure. Notice for the node labelled bcast_onestage that the maximum computation, communication, and idle time are each 19 seconds. That is, a total of 38 seconds is spent in the one-stage broadcast. However, some of the processes spend 19 seconds idling during this 38 seconds---this idle time is due to the processes waiting for the broadcasting process to transmit all the messages.